프로젝트 상의 게시글(Post)과 댓글(Comment)에 각각 좋아요 기능이 구현되어야 했다.
첫 번째 구현한 방법은 아래 ERD 다이어그램과 같다.
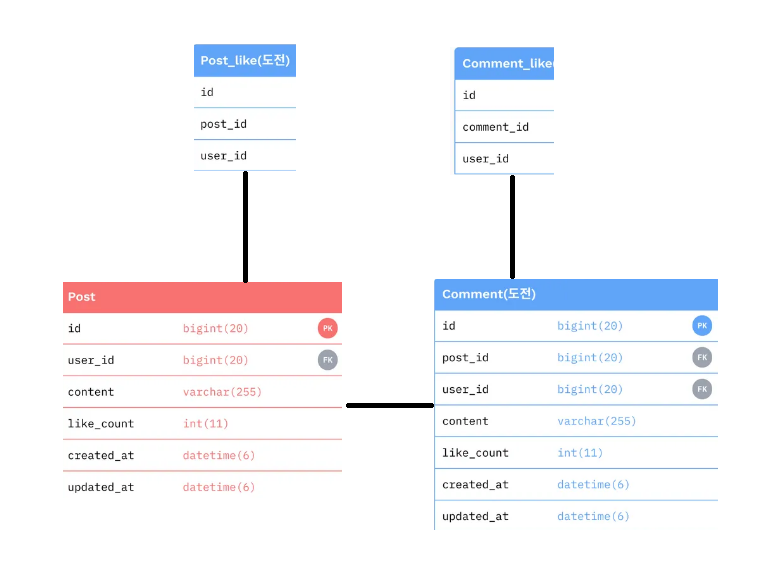
좋아요 기능이 유저-게시글 / 유저-댓글의 형태로 중복이 되지 않게 하나만 존재하게 하는 방법에 대해서도 고민 했는데, 처음에는 검증을 하려고 생각했으나 더 좋은 방법이 있었다.
다중 컬럼을 아래 코드와 같이 unique 제약조건을 사용해 묶었다.
여기서의 문제점은 굳이 UniqueConstraint를 사용할 필요가 없었던 것이다.
Service에서 해당되는 행이 존재하면 삭제하는 동작이 있기 때문이다.
@Table(uniqueConstraints ={
@UniqueConstraint(name = "user_like_comment",
columnNames = {
"user_id",
"comment_id"
})
})
@Entity
@NoArgsConstructor
@Getter
public class CommentLike {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToOne
@JoinColumn(name = "user_id", nullable = false)
private User user;
@ManyToOne
@JoinColumn(name = "comment_id", nullable = false)
@OnDelete(action = OnDeleteAction.CASCADE)
private Comment comment;
public CommentLike(User user, Comment comment) {
this.user = user;
this.comment = comment;
}
}
프로젝트가 끝난 후, 강의를 듣다가 다른 방법을 찾을 수 있었는데 바로 조인 전략이었다.
Like 엔티티를 생성한 후 type 필드를 추가하여 게시글에 달린 좋아요와 댓글의 달린 좋아요를 구분하는 방법이었다.
두 방법에 대한 차이
| 기준 | 1번 별도 테이블만들기(PostLike, CommentLike) | 2번 Like 테이블에 type 구분 |
| 데이터 구조 | 데이터 구조가 이해하기 쉬움. 특정 도메인에 집중하여 유지보수 용이. |
데이터베이스 구조가 단순해짐. 통합적으로 구성되어 있어 한 곳에서 관리 가능. type 값에 따라 다른 엔티티와 연관되므로 데이터 무결성이 깨질 위험 있음. |
| 성능 | 특정 도메인 쿼리 실행 시 불필요한 데이터를 스캔하지 않아 성능이 좋을 수 있음 인덱스 최적화도 각 테이블에 맞게 설계 가능 |
좋아요 조회 시 type에 대한 필터가 필요하므로 성능이 저하될 가능성이 있음 하나의 테이블에 모든 좋아요가 저장되어 데이터 양이 많아질수록 조회 성능 저하될 수 있음. |
| 확장성 | 쉽게 확장할 수 있음 | 만약 게시글의 좋아요와 댓글의 좋아요가 다른 특정 속성이 필요하다면 확장이 어려움 |
| 쿼리 복잡도 | 조인 또는 다중쿼리가 필요함 | 단일쿼리로 가능 |
| 테이블 관리 | 관리해야할 테이블 많음 | 단일 테이블 |
끝으로 보통의 대형 SNS(페북, 인스타, x)의 경우는 데이터 구조 직관성, 성능 최적화, 확장 가능성 때문에 1번 방법을 선호하는 편이라고 한다.
'Project' 카테고리의 다른 글
| 티켓 발급 서비스에서 JPA 낙관적 락 구현 (0) | 2025.03.27 |
|---|---|
| [404 NOT DELIVERY] Review 가게별 조회 기능 개선하기 (0) | 2025.01.13 |
| [newsfeed] Like 기능의 성능 개선하기 (0) | 2024.12.30 |
| [Todolist] ToDoList 과제 1차 TIL - 필수 구현까지 (0) | 2024.12.05 |

